Watchdog timers are a prevalent mechanism for helping to ensure embedded system reliability. But they only work if you use them properly. Effective watchdog timer use requires that the failure of any periodic task in the system must result in a watchdog timer reset.
Consequences: Improper use of a watchdog timer leads to a false sense of security in which software task deaths and software task time overruns are not detected, causing possible missed deadlines or partial software failures.
Accepted Practices:

Once the watchdog kicks a system reset is the most common reaction, although in some cases a permanent shutdown of the system is preferable if it is deemed better to wait for maintenance intervention before attempting a restart.
Getting the expected benefit from a watchdog timer requires using it in a proper manner. For example, having a hardware timer interrupt trigger unconditional kicking of the watchdog is a specifically bad practice, because it doesn’t indicate that any software task except the hardware timer ISR is working properly. (By analogy, having your teenager set up a computer to automatically call home with a prerecorded “I’m OK” message every hour on Saturday night doesn’t tell you that she’s really OK on her date.)
For a system with multiple tasks it is essential that each and every task contribute to the watchdog being kicked. Hearing from just one task isn’t enough – all tasks need to have some sort of unanimous “vote” on the watchdog being kicked. Correspondingly, a specific bad practice is to have one task or ISR report in that it is running via kicking the watchdog, and infer that this means all other tasks are executing properly. (Again by analogy, hearing from one of three teenagers out on different dates doesn’t tell you how the other two are doing.) As an example, the watchdog “should never be kicked from an interrupt routine” (MISRA Report 3, p. 38), which in general refers to the bad practice of using a timer service ISR to kick the watchdog.
A related bad practice is assuming that if a low priority task is running, this means that all other tasks are running. Higher priority tasks could be “dead” for some reason and actually give more time for low priority tasks to run. Thus, if a low priority task kicks the watchdog or sets a flag that is the sole enabling data for an ISR to kick the watchdog, this method will fail to detect if other tasks have failed to run in a timely periodic manner.
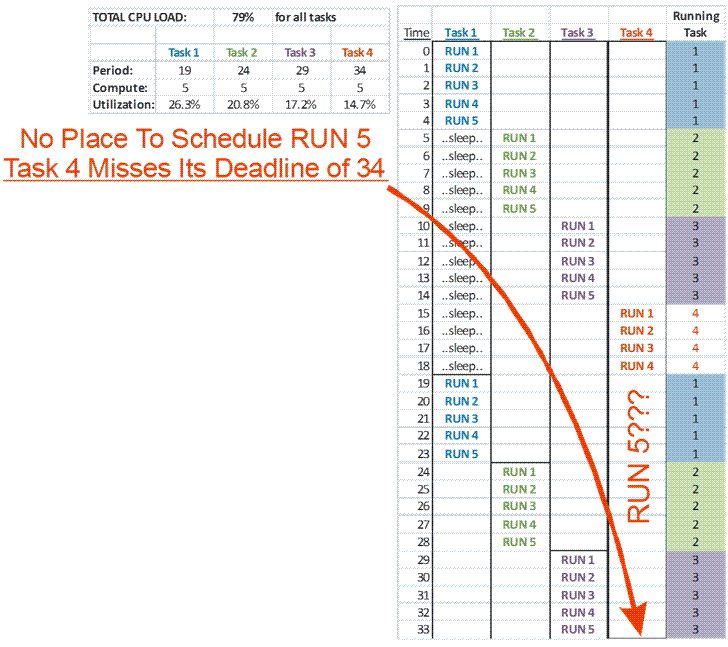
Monitoring CPU load is not a substitute for a watchdog timer. Tasks can miss their deadlines even with CPU loads of 70%-80% because of bursts of momentary overloads that are to be expected in a real time operating system environment as a normal part of system operation. For this reason, another bad practice is using software inside the system being monitored to perform a CPU load analysis or other indirect health check and kick the watchdog periodically by default unless the calculation indicates a problem. (This is a variant of kicking the watchdog from inside an ISR.)
The system software should not be in charge of measuring workload over time -- that is the job of the watchdog. The software being monitored should kick the watchdog if it is making progress. It is up to the watchdog mechanism to decide if progress is fast enough. Thus, any conditional watchdog kick should be done just based on liveness (have tasks actually been run), and not on system loading (do we think tasks are probably running).
One way to to kick a watchdog timer in a multi-tasking system is sketched by the below graphic:

Setting the timing of the watchdog system is also important. If the goal is to ensure that a task is being executed at least every 5 msec, then setting the watchdog timer at 800 msec doesn’t tell you there is a problem until that task is 795 msec late. Watchdog timers should be set reasonably close to the period of the slowest task that is kicking them, with just a little extra time beyond what is required to account for execution variation and scheduling jitter.
If watchdog timer resets are seen during testing they should be investigated. If an acceptable real time scheduling approach is used, a watchdog timer reset should never occur unless there has been system failure. Thus, finding out the root cause for each watchdog timer reset recorded is an essential part of safety critical design. For example, in an automotive context, any watchdog timer event recordings could be stored in the vehicle until it is taken in for maintenance. During maintenance, a technician’s computer should collect the event recordings and send them back to the car’s manufacturer via the Internet.
While watchdog timers can't detect all problems, a good watchdog timer implementation is a key foundation of creating a safe embedded control system. It is a negligent design omission to fail to include an acceptable watchdog timer in a safety critical system.
Watchdog timers are a classical approach to ensuring system reliability, and are a pervasive hardware feature on single-chip microcontrollers for this reason.
An early scholarly reference is a survey paper of existing approaches to industrial process control (Smith 1970, p. 220). Much more recently, Ball discusses the use of watchdog timers, and in particular the need for every task to participate in kicking the watchdog. (Ball 2002, pp 81-83). Storey points out that while they are easy to implement, watchdog timers do have distinct limitations that must be taken into account (Storey pg. 130). In other words, watchdog timers are an important accepted practice that must be designed well to be effective, but even then they only mitigate some types of faults.
Lantrip sets forth an example of how to ensure multiple tasks work together to use a watchdog timer properly. (Lantrip 1997). Ganssle discusses how to arrange for all tasks to participate in kicking the watchdog, ensuring that some tasks don’t die while others stay alive. (Ganssle 2000, p. 125).
Brown specifically discusses good and bad practices. “I’ve seen some multitasking systems that use an interrupt to tickle the watchdog. This approach defeats the whole purpose for having one in the first place. If all the tasks were blocked and unable to run, the interrupt method would continue to service the watchdog and the reset would never occur. A better solution is to use a separate monitor task that not only tickles the watchdog, but monitors the other system tasks as well.” (Brown 1998 pg. 46).
The MISRA Software Guidelines recommend using a watchdog to detect failed tasks (MISRA Report 1, p. 43), noting that tasks (which they call “processes”) may fail because of noise/EMI, communications failure, software defects, or hardware faults. The MISRA Software Guidelines say that a “watchdog is essential, and must not be inhibited,” while pointing out that having returning an engine to idle in a throttle-by-wire application could be unsafe. (MISRA Report 1, p. 49). MISRA also notes that “The consequence of each routine failing must be identified, and appropriate watchdog and default action specified.” (MISRA Report 4 p. 33, emphasis added)
NASA recommends using a watchdog and emphasizes that it must be able to detect death of all tasks (NASA 2004, p. 93). IEC 61508-2 lists a watchdog timer as a form of test by redundant hardware (pg. 115) (without implying that it provides complete redundancy).
Addy identified a task death failure mode in a case study (Addy 1991, pg. 79) due to a task encountering a run-time fault that was not properly caught, resulting in the task never being restarted. Thus, it is reasonably conceivable that a task will die in a multitasking operating system. Inability to detect a task death is a defect in a watchdog timer, and a defective watchdog timer approach undermines the safety of the entire system. With such a defective approach, it would be expected that task deaths or other foreseeable events will go undetected by the watchdog timer.
References:
Consequences: Improper use of a watchdog timer leads to a false sense of security in which software task deaths and software task time overruns are not detected, causing possible missed deadlines or partial software failures.
Accepted Practices:
- If multiple periodic tasks are in the system, each and every such task must contribute directly to the watchdog being kicked to ensure every task is alive.
- Use of a hardware timer interrupt to directly kick the watchdog is a bad practice. (There is arguably an exception of the ISR keeps a record of all currently live tasks as described later.)
- Inferring task health by monitoring the lowest priority task alone is a bad practice. This approach fails to detect dead high priority tasks.
- The watchdog timeout period should be set to the shortest practical value. The system should remain safe even if any combination of tasks dies for the entire period of the watchdog timeout value.
- Every time the watchdog timer reset happens during testing of a fully operational system, that fact should be recorded and investigated.
Briefly, a watchdog timer can be thought of as a counter that starts at some predetermined value and counts down to zero. If the watchdog actually gets to zero, it resets the system in the hopes that a system reset will fix whatever problem has occurred. Preventing such a reset requires “kicking” (terms for this vary) the watchdog periodically to set the count back at the original value, preventing a system reset. The idea is for software to convince the hardware watchdog that the system is still alive, forestalling a reset. The idea is not unlike asking a teenager to call in every couple hours on a date to make sure that everything is going OK.
Watchdog timer arrangement.
Once the watchdog kicks a system reset is the most common reaction, although in some cases a permanent shutdown of the system is preferable if it is deemed better to wait for maintenance intervention before attempting a restart.
For a system with multiple tasks it is essential that each and every task contribute to the watchdog being kicked. Hearing from just one task isn’t enough – all tasks need to have some sort of unanimous “vote” on the watchdog being kicked. Correspondingly, a specific bad practice is to have one task or ISR report in that it is running via kicking the watchdog, and infer that this means all other tasks are executing properly. (Again by analogy, hearing from one of three teenagers out on different dates doesn’t tell you how the other two are doing.) As an example, the watchdog “should never be kicked from an interrupt routine” (MISRA Report 3, p. 38), which in general refers to the bad practice of using a timer service ISR to kick the watchdog.
A related bad practice is assuming that if a low priority task is running, this means that all other tasks are running. Higher priority tasks could be “dead” for some reason and actually give more time for low priority tasks to run. Thus, if a low priority task kicks the watchdog or sets a flag that is the sole enabling data for an ISR to kick the watchdog, this method will fail to detect if other tasks have failed to run in a timely periodic manner.
Monitoring CPU load is not a substitute for a watchdog timer. Tasks can miss their deadlines even with CPU loads of 70%-80% because of bursts of momentary overloads that are to be expected in a real time operating system environment as a normal part of system operation. For this reason, another bad practice is using software inside the system being monitored to perform a CPU load analysis or other indirect health check and kick the watchdog periodically by default unless the calculation indicates a problem. (This is a variant of kicking the watchdog from inside an ISR.)
The system software should not be in charge of measuring workload over time -- that is the job of the watchdog. The software being monitored should kick the watchdog if it is making progress. It is up to the watchdog mechanism to decide if progress is fast enough. Thus, any conditional watchdog kick should be done just based on liveness (have tasks actually been run), and not on system loading (do we think tasks are probably running).
One way to to kick a watchdog timer in a multi-tasking system is sketched by the below graphic:
Key attributes of this watchdog approach are: (1) all tasks must be alive to kick the WDT. If even one task is dead the WDT will time out, resetting the system. (2) The tasks do not keep track of time or CPU load on their own, making it impossible for them to have a software defect or execution defect that “lies” to the WDT itself about whether things are alive. Rather than making the CPU’s software police itself and shut down to await a watchdog kick if something is wrong, this software merely has the tasks report in when they finish execution and lets the WDT properly due its job of policing timeliness. More sophisticated versions of this code are possible depending upon the system involved; this is a classroom example of good watchdog timer use. Where "taskw" is run from depends on the scheduling strategy and how tight the watchdog timer interval is, but it is common to run it in a low-priority task.
Setting the timing of the watchdog system is also important. If the goal is to ensure that a task is being executed at least every 5 msec, then setting the watchdog timer at 800 msec doesn’t tell you there is a problem until that task is 795 msec late. Watchdog timers should be set reasonably close to the period of the slowest task that is kicking them, with just a little extra time beyond what is required to account for execution variation and scheduling jitter.
If watchdog timer resets are seen during testing they should be investigated. If an acceptable real time scheduling approach is used, a watchdog timer reset should never occur unless there has been system failure. Thus, finding out the root cause for each watchdog timer reset recorded is an essential part of safety critical design. For example, in an automotive context, any watchdog timer event recordings could be stored in the vehicle until it is taken in for maintenance. During maintenance, a technician’s computer should collect the event recordings and send them back to the car’s manufacturer via the Internet.
While watchdog timers can't detect all problems, a good watchdog timer implementation is a key foundation of creating a safe embedded control system. It is a negligent design omission to fail to include an acceptable watchdog timer in a safety critical system.
Selected Sources
An early scholarly reference is a survey paper of existing approaches to industrial process control (Smith 1970, p. 220). Much more recently, Ball discusses the use of watchdog timers, and in particular the need for every task to participate in kicking the watchdog. (Ball 2002, pp 81-83). Storey points out that while they are easy to implement, watchdog timers do have distinct limitations that must be taken into account (Storey pg. 130). In other words, watchdog timers are an important accepted practice that must be designed well to be effective, but even then they only mitigate some types of faults.
Lantrip sets forth an example of how to ensure multiple tasks work together to use a watchdog timer properly. (Lantrip 1997). Ganssle discusses how to arrange for all tasks to participate in kicking the watchdog, ensuring that some tasks don’t die while others stay alive. (Ganssle 2000, p. 125).
Brown specifically discusses good and bad practices. “I’ve seen some multitasking systems that use an interrupt to tickle the watchdog. This approach defeats the whole purpose for having one in the first place. If all the tasks were blocked and unable to run, the interrupt method would continue to service the watchdog and the reset would never occur. A better solution is to use a separate monitor task that not only tickles the watchdog, but monitors the other system tasks as well.” (Brown 1998 pg. 46).
The MISRA Software Guidelines recommend using a watchdog to detect failed tasks (MISRA Report 1, p. 43), noting that tasks (which they call “processes”) may fail because of noise/EMI, communications failure, software defects, or hardware faults. The MISRA Software Guidelines say that a “watchdog is essential, and must not be inhibited,” while pointing out that having returning an engine to idle in a throttle-by-wire application could be unsafe. (MISRA Report 1, p. 49). MISRA also notes that “The consequence of each routine failing must be identified, and appropriate watchdog and default action specified.” (MISRA Report 4 p. 33, emphasis added)
NASA recommends using a watchdog and emphasizes that it must be able to detect death of all tasks (NASA 2004, p. 93). IEC 61508-2 lists a watchdog timer as a form of test by redundant hardware (pg. 115) (without implying that it provides complete redundancy).
Addy identified a task death failure mode in a case study (Addy 1991, pg. 79) due to a task encountering a run-time fault that was not properly caught, resulting in the task never being restarted. Thus, it is reasonably conceivable that a task will die in a multitasking operating system. Inability to detect a task death is a defect in a watchdog timer, and a defective watchdog timer approach undermines the safety of the entire system. With such a defective approach, it would be expected that task deaths or other foreseeable events will go undetected by the watchdog timer.
- Addy, E., A case study on isolation of safety-critical software, Proc. Conf Computer Assurance, pp. 75-83, 1991.
- Ball, Embedded Microprocessor Systems: Real World Design, Newnes, 2002.
- Brown, D., “Solving the software safety paradox,” Embedded System Programming, December 1998, pp. 44-52.
- Ganssle, J., The Art of Designing Embedded Systems, Newnes, 2000.
- IEC 61508, Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems (E/E/PE, or E/E/PES), International Electrotechnical Commission, 1998.
- Lantrip, D. & Bruner, L., General purpose watchdog timer component for a multitasking system, Embedded Systems Programming, April 1997, pp. 42-54.
- MISRA, Report 1: Diagnostics and Integrated Vehicle Systems, February 1995.
- MISRA, Report 3: Noise, EMC and Real-Time, February 1995.
- MISRA, Report 4: Software in Control Systems, February 1995.
- NASA-GB-8719.13, NASA Software Safety Guidebook, NASA Technical Standard, March 31, 2004.
- Smith, Digital control of industrial processes, ACM Computing Surveys, Sept. 1970, pp. 211-241.
- Storey, N., Safety Critical Computer Systems, Addison-Wesley, 1996.